Everyone of us developers mainly working in the web development world have at some point in time have heard of the word rate-limiting. In this article I have to tried to simplify what rate limiting is and how can we can implement it in Golang. Let’s understand all these things step by step.
What is rate Limiting?
Rate Limiting simply means limiting the the number of times a user can request a particular resource / service in a given time-frame. To ensure that all the clients of the service use the service optimally. The rate limiting is both a prevention and quality control measure. Okay! Enough of buzz words and jargons let’s understand this in a simplified manner with the help of diagram below.
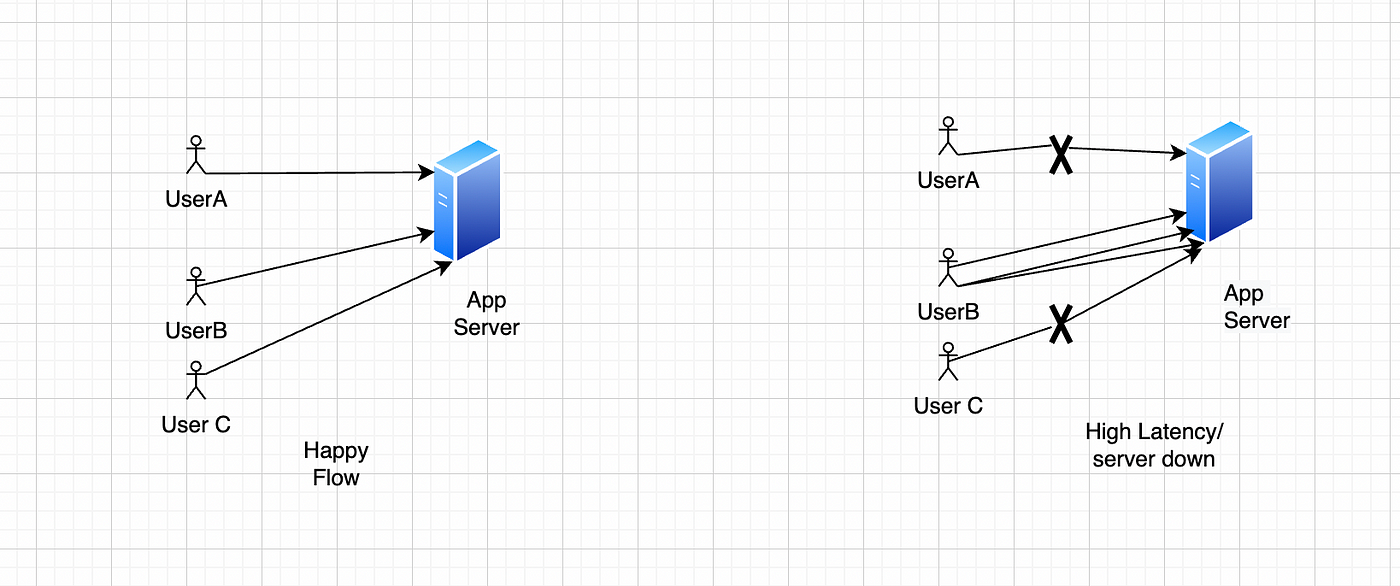
Let’s say we have 3 users A,B and C all hitting some API on our server. Also let’s predefine that the maximum request load our hypothetical server can handle is 3 requests/second. In happy flow all the users will get a usual happy case response. Fine till now, but let’s say that userB starts hitting our api with rate of 3 hits/second. Now in this case when user A and user B try to use our API they will start experiencing very high latency in response or connection timeouts thus resulting in bad experience for user A and user C. This is where rate limiting comes into the picture, what rate limiter will do is that when the userB tries to hit the 2nd request in the same second. It will simply discard that request. Thus rate limiting ensures the fair usage of services and other resources by clients. So that all clients have fair experience.
Token Bucket Algorithm
Now we know what does the rate limiting means. Let’s see how we can implement this functionality in our application server. One of the most easy to understand algorithm for rate limiting is the token bucket algorithm. Now let’s understand what does this algorithm is:
Let’s say that we have a hypothetical bucket of size X (i.e it can contain at max X tokens) and let’s say that whenever a user make a request he uses some of the tokens from this bucket, simultaneously this bucket keeps on refilling itself at a constant rate let’s say Y tokens/second. But don’t forget that the bucket can never have more than X tokens at any time t.

Let’s understand with a graphical example so that things become more clear.

Let’s say that our bucket has a max capacity of 10 tokens and it has constant token filling rate of 10 tokens / second.
1. At t0=0ms the bucket was full with 10 tokens.
2. At t1 = 300ms the userX makes an api request that is bound to consume 6 tokens. so we use the 6 tokens and remove the used tokens from the bucket.
(Note: You must be wondering that if the rate of fulfilling was constant then why did not we do the token filling, the reason for this is that we do the filling step before performing the tokens check and since the bucket was already at full capacity at t1 = 300ms and hence nothing could be added to it, also we set the time for the last refill in order to calculate how much time has escaped since last refill occurred and add the difference of the tokens that take place in this time).
3. Again at t2 = 500 ms the userX comes and makes another request that costed the 5 tokens. But since we are filling the bucket at constant rate and last refill try happened at the t = t1 = 300 ms. so the time that has escaped since the last refill = 200ms and the no. of token that needs to be added=2.
4. Again at t3 = 1500ms when user again returns the bucket will become full as the difference since the last refill is 1000ms and since the refill rate was 10 tokens / second. The bucket will be filled to full capacity with value=10.
The reasons that make the token bucket algorithm a very powerful one is that it is easy to implement, it’s memory bounded and fast.
Implementation
So we have learned what token bucket algorithm is. Let’s look at the implementation.
Firstly Let’s define some core structures that we will be using:

The TokenBucket is the core structure that will implement all the operations on the bucket.
1. rate -> represents the rate at which the bucket should be filled.
2. maxTokens -> represents the max tokens capacity that the bucket can hold.
3. currentTokens -> tokens currently present in the bucket at any time t.
4. lastRefillTimestamp -> this represents the last time t the bucket fill operation was tried.
5. mutex -> as many concurrent requests can come simultaneously but the addition and subtraction of tokens from the bucket should be synchronised and hence each bucket object contains a mutex.
Now Let’s define some operations on this bucket. As we saw in the algorithm the two basic operation we need to support is wether to accept or reject a request based on available tokens and filling the bucket at constant rate. Let’s see how to support these operations.
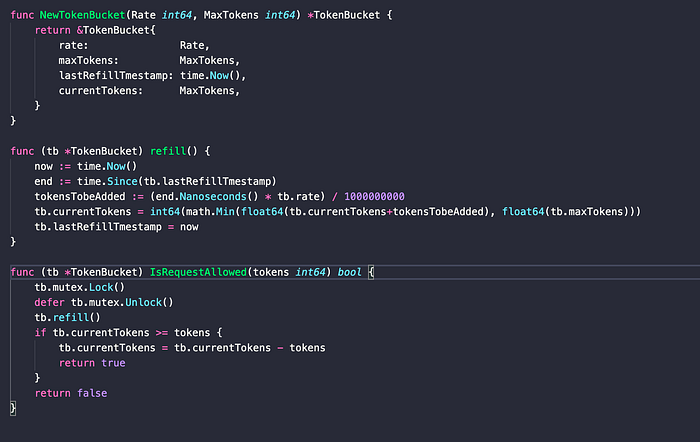
The NewTokenBucket returns a new bucket for a client if the client doesn’t exist in the system and sets his current tokens to the max tokens.
The refill method refills the number of tokens needed to be added since the time elapsed after last refill. Also we will reset the lastRefillTimeStamp in this for the next request.
The IsRequestAllowed method is the one which takes the decision wether the request should be discarded or not. It first refills the clients bucket and after that checks if the client can perform the required request or not.
NOTE: If you search on net you might see implementations of token bucket rate limiter where the refill method is run in a background thread that continuously run and fills bucket at constant rate. But I think this above implementation makes more sense as this only performs refills when required because let’s say the user came at t0=0ms and then the next time user visits for the same request at t1=1 hour. In this 1 hour we will be resetting the bucket capacity to 10 again and again which doesn’t make much sense.
You can see that IsRequestAllowed is thread safe with the help of mutex, the reason is that the user might fire concurrent requests and then we will have race conditions for token state.
That’s it this is the full implementation of the token bucket algorithm. Now let’s see how we can use this to rate limit your API endpoints. But before that we need to understand that the user can be of different types and you might have a need to set different types of fill rate and limiting factor depending on it.
So I have create a rule.go file that creates a client bucket depending on the user type. This is a demo representation you can define rules based on a number of factors.
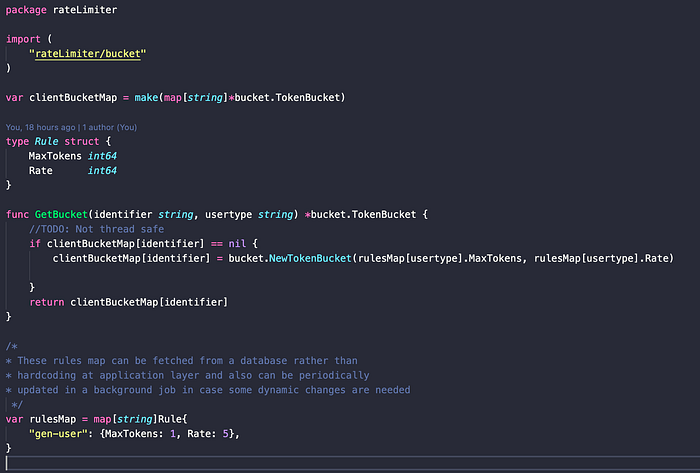
The GetBucket method creates a client bucket if not exists and returns it. The rules for this client are fetched using the rules map. Now these rules can be dynamic in nature and this can be updated through a background job. To keep this article simple and engaging I have skipped all these steps.
Now let’s come to the final step i.e. actually using this tokenBucket for rate-limiting our API. To have a working demonstration I have simply used the gin-gonic framework through which can create a http-server very easily.

In our main function we have created a http-server that listens on port 8080.
In InitRoutes function I have registered a GET /hello endpoint that does nothing but simply return a hello message as json response.
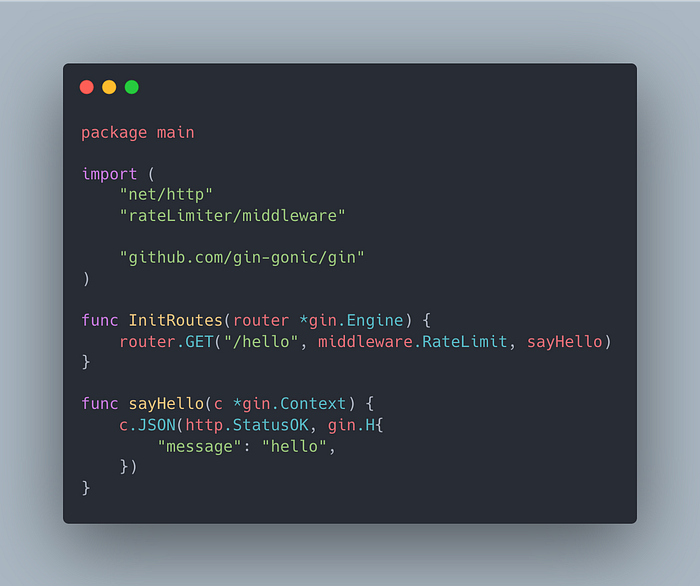
You must be wondering that while registering the /hello route I have written middleware.RateLimit in between what does this do. The gin routes provides a functionality to register multiple functions as middleware in a chain for an endpoint (This follows a chain of responsibility pattern but since this article is not about it I will leave it to you guys to learn about it more :P). So before our request goes to the actual processing function that is the sayHello(NOTE: In real world this can be a more complicated handler function that does a lot of processing and takes a lot of time to execute) we first pass it to our RateLimit handler. Let’s see what does the RateLimit Handler does.
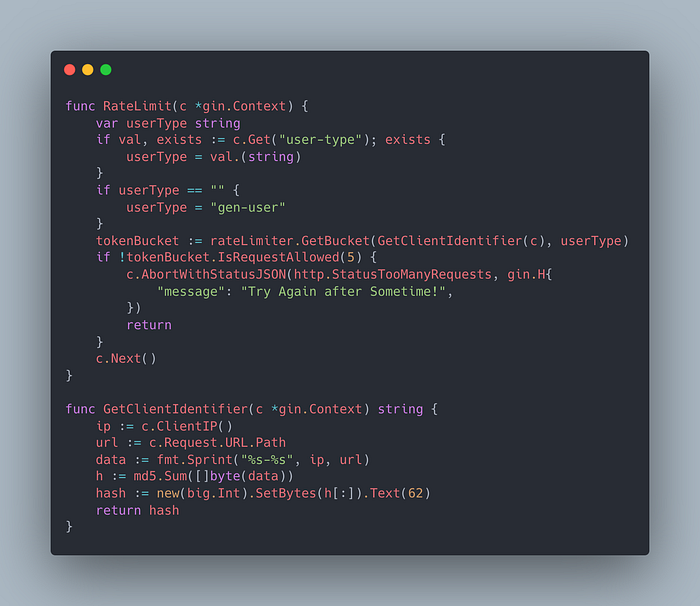
Inside the rateLimit handler function we first fetch the bucket for this client identifier and of the gen-user usertype. If you closely see the implementation of the GetClientIdentifier you will see that I have taken the clientIp and the api path into consideration to create this unique identifier the reason I did this is because I wanted to limit the client per API end point basis and then I have returned the base62EncodedValue of md5 (hashing technique) of concatenated string of client IP and raw path. After that I just called the IsRequestAllowed method on this client’s bucket. Now if the request should pass then it is passed on the next handler in the chain i.e sayHello in our case (c.Next() does this). Otherwise I simply abort this request with a json response of “Try Again after some time!” and statusCode of 429(Too many requests). That’s it that is the most basic way of implementing rate Limiting in your API server.
You can check the full code at https://github.com/hbk-007/go-rate-limiter
LIMITATIONS
- Our algorithm is well and good if we just had one server. But in case of distributed env. we will be having multiple servers in that case we use a slightly modified version of our rate Limiter where the all the server nodes communicate with each other that how many tokens have been used in totality by some clientX that is a different problem altogether.
- Other problems include processing the more requests than allowed when requests are fired just after the refilling. Refer this link for better understanding https://stackoverflow.com/questions/65868274/token-bucket-vs-fixed-window-traffic-burst
Wrapping It up
Rate limiting is an important paradigm for APIs to help protect against malicious bot attacks as well as making sure that there is a fair and controlled usage of resource and services.
NOTE: I have skipped many details in this article to keep it simple and engaging. You are free to explore more on rate Limiting, there are excellent videos on youtube for the same.
If you found this helpful, click the 💚 so more people will see it here on Medium.
